前言
快过年了,想起高中时每年语文老师都会朗读习近平主席的金句名言,以开阔同学们的眼界、猜测高考热点。想到这,心里感慨万千。最近也在复习爬虫的相关知识,于是爬取了三篇习大大的新年贺词,统计词频并生成词云,关注一波近年来我国的热点。
测试环境: Python3.6、win10
第三方库:requests、beautifulsoup、re、WordCloud等
问题分析
爬虫部分
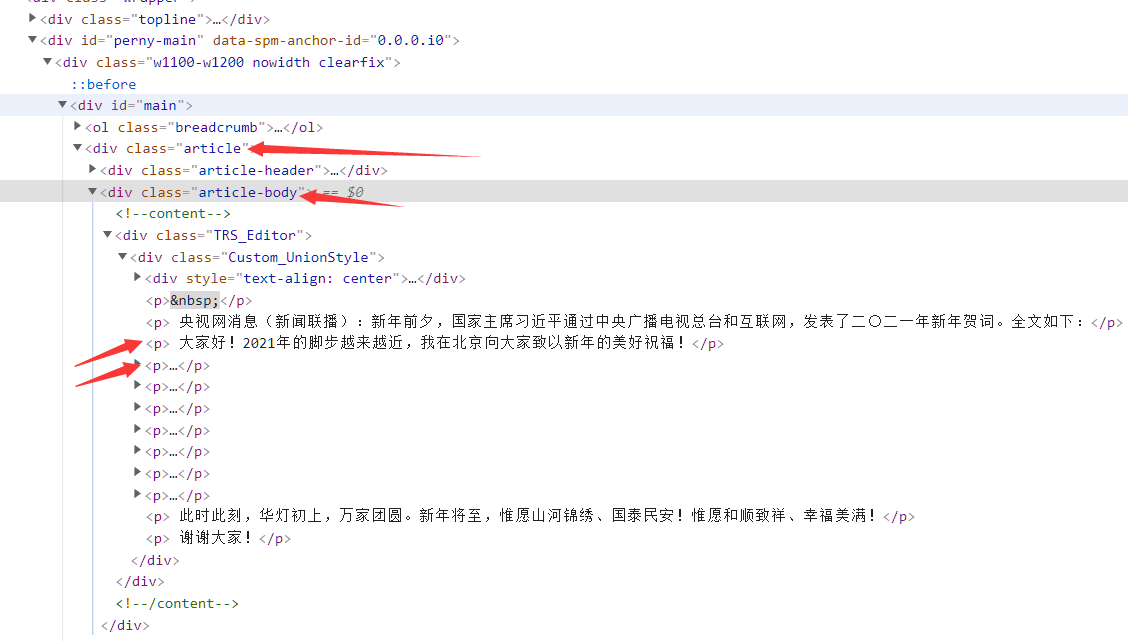
我们需要爬取习大大近三年的新年贺词,这里选择央广网
近三年来,网站的内容均在类名为article-body的div盒子下,且均为p标签(只有2022年的文章内容给予p标签样式,不通用)

利用soup确定文本位置,将三篇贺词写入text.txt,我们便完成了爬虫部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def getHtml(url, head):
r = requests.get(url, headers=head, timeout=30)
r.raise_for_status()
r.encoding = "GBK"
print("网页请求成功!")
return r.text
def getSoupText(html):
soup = BeautifulSoup(html, "html.parser")
ps = soup.find('div', 'article-body').find_all('p')
with open("text.txt", 'a', encoding="utf-8") as f:
for p in ps:
f.write(str(p.get_text()))
f.write('\n')
f.close()
|
清洗部分
这里使用了哈工大的停词表清洗text中的无用词汇,排除中文无用虚词"了"的词汇的影响,利用collections库一行代码完成词频统计,并输出词频前十的词条。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def textSolve():
result = []
text = open("text.txt", encoding="utf-8").read()
strs = re.sub("[\s+\.\!\-\/_,$%^*<>《》()+\"\']+|[+——!,。?、~@#¥%……&*():”“]", "", text)
strs = jieba.cut(strs)
with open("hit_stopwords.txt", 'r', encoding='utf-8') as f:
remove_words = [w.strip('\n') for w in f.readlines()]
for word in strs:
if word not in remove_words:
result.append(word)
wordCounts = collections.Counter(result)
wordCountsTop10 = wordCounts.most_common(10)
print (wordCountsTop10)
return wordCounts
|
词云生成
备忘:词云生成的数据必须为字典类型,存储词条内容与频数的键值对,可以通过font的路径更换生成词云的字体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def ShowCloud(maskPath, fontPath, fileName, wordCounts):
mask = np.array(Image.open(maskPath))
wc = wordcloud.WordCloud(
font_path=fontPath,
mask=mask,
max_words=200,
max_font_size=100,
background_color='white'
)
wc.generate_from_frequencies(wordCounts)
image_colors = wordcloud.ImageColorGenerator(mask)
wc.recolor(color_func=image_colors)
wc.to_file('name.jpg')
print("请查看name.jpg")
|
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
import requests
from bs4 import BeautifulSoup
import re
import jieba
import collections
import numpy as np
import wordcloud
from PIL import Image
def getHtml(url, head):
r = requests.get(url, headers=head, timeout=30)
r.raise_for_status()
r.encoding = "GBK"
print("网页请求成功!")
return r.text
def getSoupText(html):
soup = BeautifulSoup(html, "html.parser")
ps = soup.find('div', 'article-body').find_all('p')
with open("text.txt", 'a', encoding="utf-8") as f:
for p in ps:
f.write(str(p.get_text()))
f.write('\n')
f.close()
def textSolve():
result = []
text = open("text.txt", encoding="utf-8").read()
strs = re.sub("[\s+\.\!\-\/_,$%^*<>《》()+\"\']+|[+——!,。?、~@#¥%……&*():”“]", "", text)
strs = jieba.cut(strs)
with open("hit_stopwords.txt", 'r', encoding='utf-8') as f:
remove_words = [w.strip('\n') for w in f.readlines()]
for word in strs:
if word not in remove_words:
result.append(word)
wordCounts = collections.Counter(result)
wordCountsTop10 = wordCounts.most_common(10)
print (wordCountsTop10)
return wordCounts
def ShowCloud(maskPath, fontPath, fileName, wordCounts):
mask = np.array(Image.open(maskPath))
wc = wordcloud.WordCloud(
font_path=fontPath,
mask=mask,
max_words=200,
max_font_size=100,
background_color='white'
)
wc.generate_from_frequencies(wordCounts)
image_colors = wordcloud.ImageColorGenerator(mask)
wc.recolor(color_func=image_colors)
wc.to_file('name.jpg')
print("请查看name.jpg")
def main():
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
urls = ["http://china.cnr.cn/news/20200101/t20200101_524921153.shtml",
"http://news.cnr.cn/native/gd/20201231/t20201231_525380797.shtml", "http://news.cnr.cn/native/gd/20211231/t20211231_525704373.shtml"]
for url in urls:
html = getHtml(url, head)
getSoupText(html)
wordCounts = textSolve()
ShowCloud('xijinping.jpg', 'C:/Windows/Fonts/SimHei.ttf', 'name.jpg', wordCounts)
main()
|
效果展示